

Pymetrics Reenvisioned: Using statistics to balance risk and reward when faced with uncertainty
Reinforcement learning is a current hot topic in the world of data science. In this post, we look at how concepts from this area, in particular effective policies for the multi-armed bandit problem, can be applied to a job application assessment ran by pymetrics.
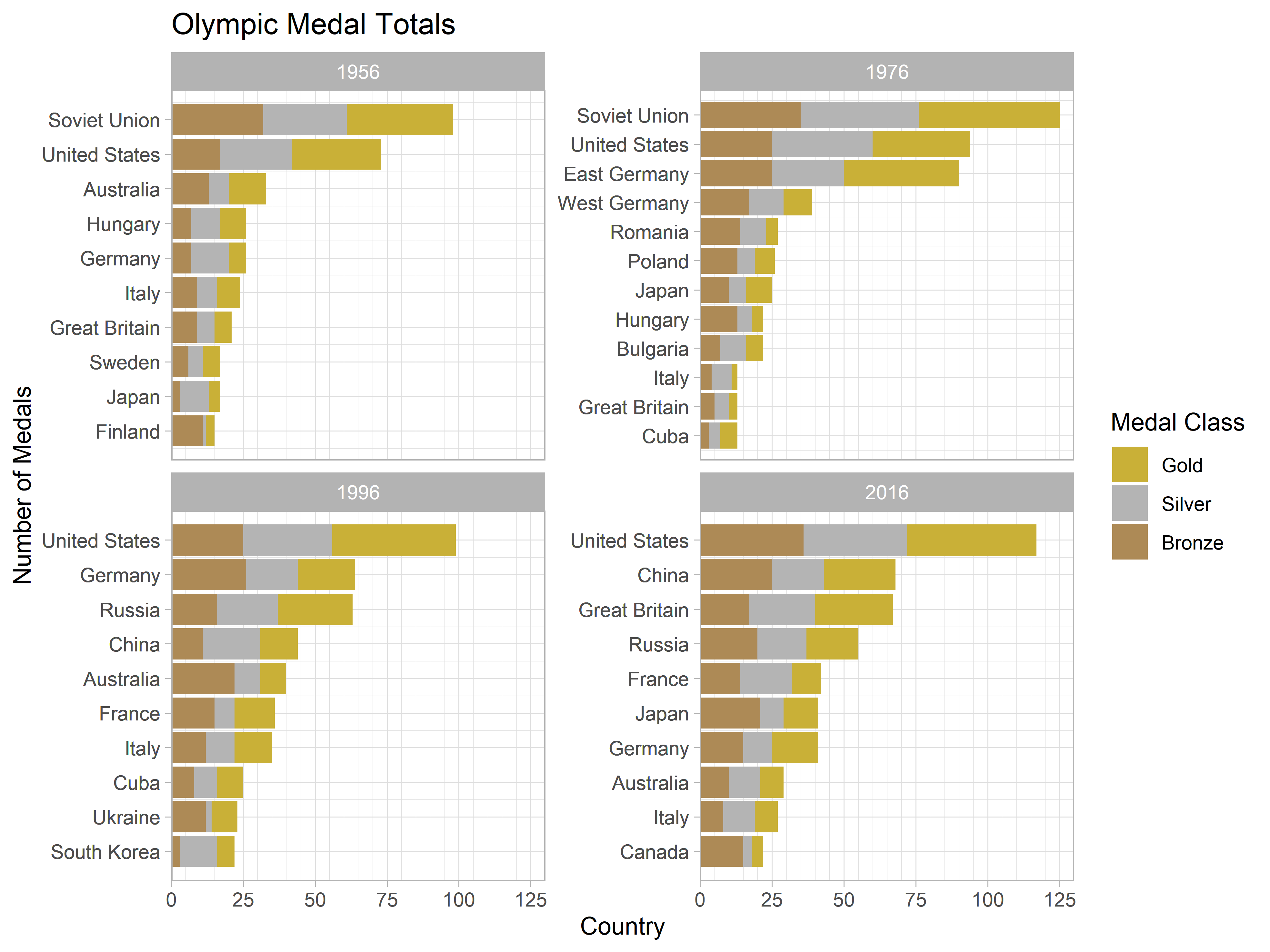
Ordering Factors within a Faceted Plot
ggplot2 is an amazing tool for building beautiful visualisations using a simple and coherent grammar—that is, when it wants to play nice. Sadly, this is not always the case and one can find themselves developing strange workarounds to overcome the limitations of the package. This post discusses one of these approaches, used to facilitate the correct ordering of factors within a faceted plot.

Maths Matters: Bouncy Numbers
When we get swept up by the data science craze, it is often all too easy to forget the importance of pure mathematics and statistics, in place of flashy new algorithms and machine learning models. As a reminder of the power of pure mathematics, this post discusses how I used a moderate knowledge of combinatorics to solve a challenging ProjectEuler+ problem with only 4 essential lines of code.
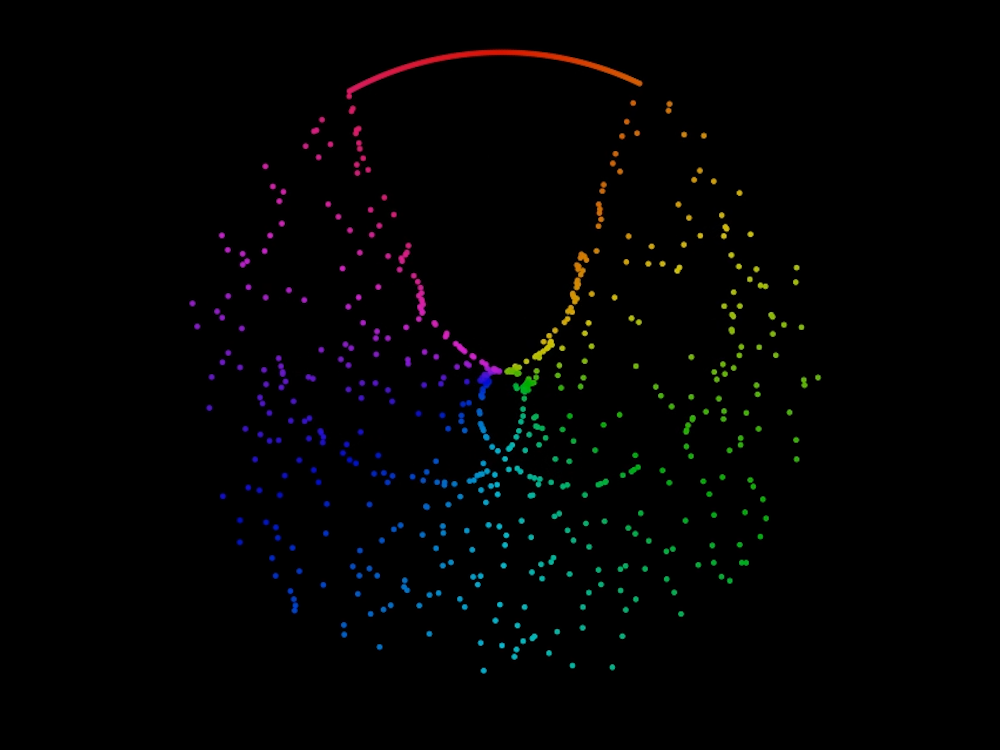
Yet Another Sorting Algorithm Visualisation
Sorting algorithms are an essential part of a computer scientist's toolbox. They are so integral to the field that there are almost endless visualisations of the algorithms at work. I've decide to jump on the band wagon and make my own contribution. In this post I discuss my visualisation method and showcase its application on a few simple sorting algorithms, explaining how such processes work in the meantime.

Enforcing Input Permanence with Shiny
Shiny is an incredibly tool for building online dashboards and web apps. The crux of Shiny is the concept reactive programming, allowing you to build visualisations and analyses which automatically update with changing user input. Reactivity is complicated though and doesn't always work as you expect so in this post I tackle an issue which I have repeatedly faced in my work and to which a solution I am yet to find online.

Upon Reflection: dunnhumby
In the first installment of this new blog post series, I will be discussing my summer internship working at the global customer data science firm, dunnhumby. In doing so, I will discuss the elements that tasks up my work, the challenges I faced in completing them, and the lessons I learnt in the process.

Bank Holiday Bodge: A Wall of Music
Sometimes, perfection overkill. In this spirit I would like to introduce a series of new blog posts - each installment of which being written and released on a UK bank holiday - in which I plan, build, and discuss a data science project all within the span of one day. In this maiden post, I use technqiues in dimensionality reduction and web-scrapping to produce a 'Wall of Music' based off the 2017/18 Spotify top 100 tracks.
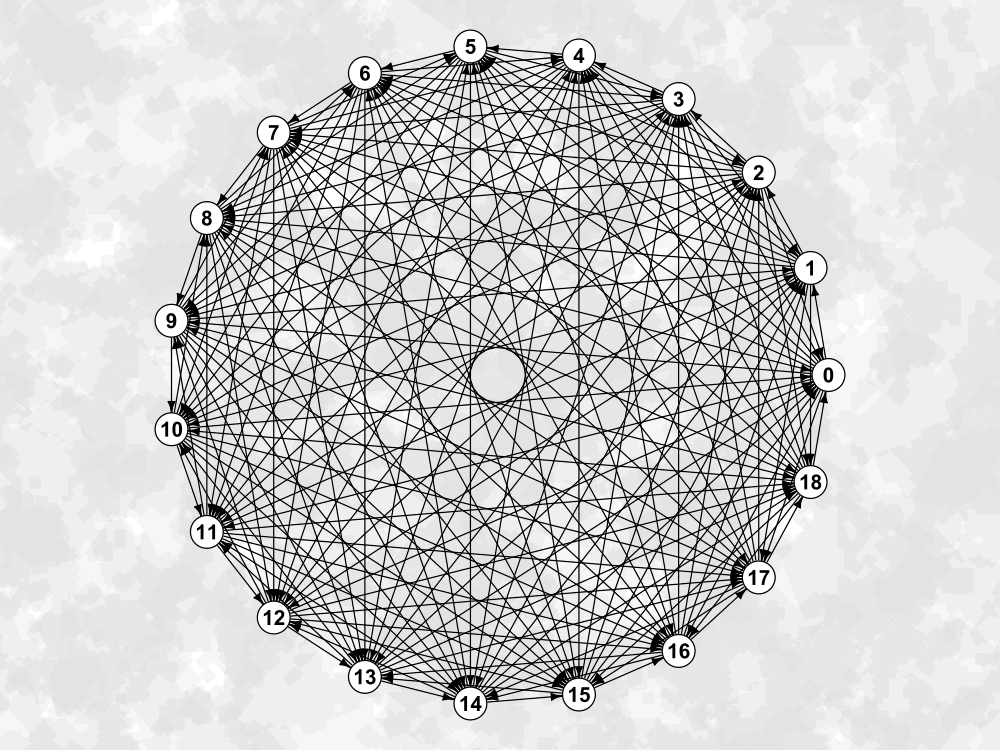
Paradoxical Tournaments
Deciding the winner of a round-robin tournament is no simple task. The most naïve approach can easily be faltered by the existence of $k$-paradoxical tournaments. But what are these tournaments and what do we know about them? There is surprisingly little discussion on the topic and so, in this post, I plan to collate various pieces of knowledge on the subject into one succinct guide.

Integrating Hexo and Jupyter to Build a Data Science Blog
When creating a data science blog, there are many different approaches that can be taken. The main two decisions revolve around how you wish to write your content and which static site generator you wish to use to build your site. For the last year I have been using RStudio, Blogdown, and Hugo to achieve this but - after much deliberation - I have decided that change is needed. This blog post follows my transition to building a data science blog powered by Jupyter and Hexo, the obstacles I came up against, and the solutions I came to employ.
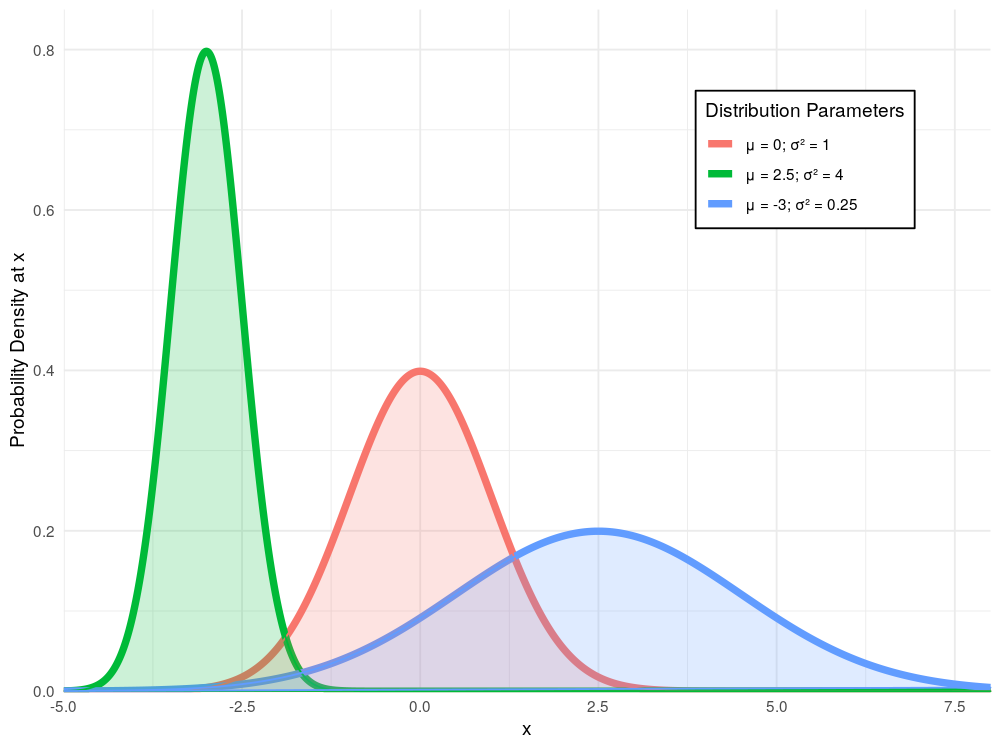
Generating Normal Random Variables - Part 1: Inverse Transform Sampling
The normal distribution is one of the most important developments in the history of statistics. As well as its useful statistical properties, it is so well-loved for its omnipresence in the natural world, appearing in all sorts of contexts from epidemiology to quantum mechanics. This blog post, the first in a series of posts discussing how we can generate random normal variables, explores the theory behind and the implementation of inverse transform sampling.
Recent



