

The Poisson Distribution Meets Modular Arithmetic
Inspired by a simple probability puzzle, I set out to determine the probability that a Poisson random variable is divisible by a given integer, before extending this result to calculate the distribution of the Poisson random variable modulo a divisor.

Reflecting on the Reflection Principle
From finance to route planning, the reflection principle is an incredibly versatile technique, capable of transforming seemingly fiendish problems into elegant systems. In this post, I walk through three example applications of the principle.

Data Roaming: A Portable Linux Environment for Data Science
When trying to fit data science in with a busy schedule of study, one often needs to work from shared university or library computers. Rather than spending the first 15 minutes of your working session reinstalling software, why not create a bootable USB stick with all your requirements ready to go?
Bank Holiday Bodge: Daily XKCD Mailer
2020 is here and one of my goals for the coming year is to finally get caught up on the XKCD comic series. Starting from the beginning is a dull way of doing things so instead I've taken advantage of Google Cloud Platform's Cloud Scheduler to setup a python script to email me a random selection of new comics each day. In this post I will share how you can do the same.
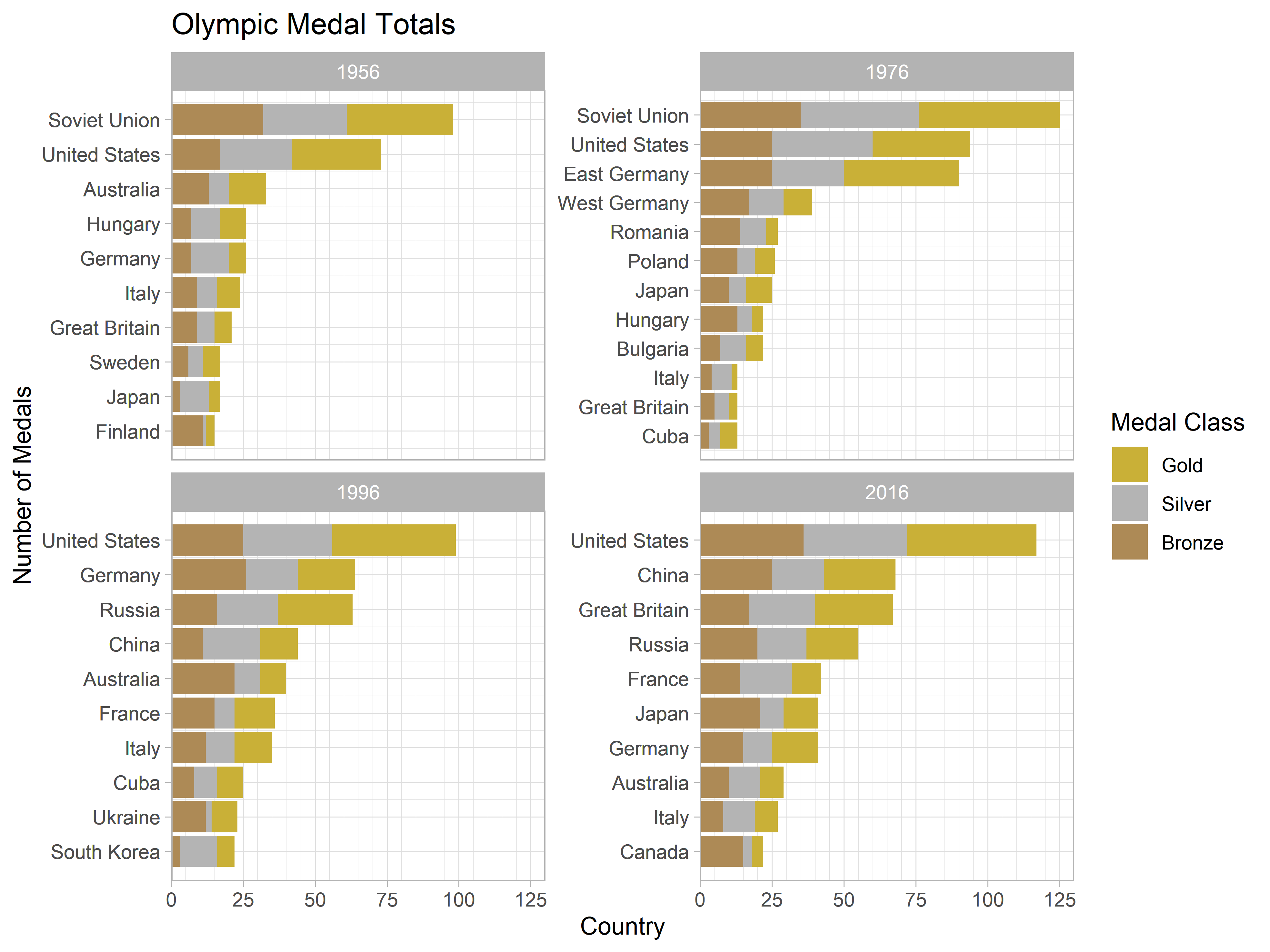
Ordering Factors within a Faceted Plot
ggplot2 is an amazing tool for building beautiful visualisations using a simple and coherent grammar—that is, when it wants to play nice. Sadly, this is not always the case and one can find themselves developing strange workarounds to overcome the limitations of the package. This post discusses one of these approaches, used to facilitate the correct ordering of factors within a faceted plot.

Enforcing Input Permanence with Shiny
Shiny is an incredibly tool for building online dashboards and web apps. The crux of Shiny is the concept reactive programming, allowing you to build visualisations and analyses which automatically update with changing user input. Reactivity is complicated though and doesn't always work as you expect so in this post I tackle an issue which I have repeatedly faced in my work and to which a solution I am yet to find online.

Integrating Hexo and Jupyter to Build a Data Science Blog
When creating a data science blog, there are many different approaches that can be taken. The main two decisions revolve around how you wish to write your content and which static site generator you wish to use to build your site. For the last year I have been using RStudio, Blogdown, and Hugo to achieve this but - after much deliberation - I have decided that change is needed. This blog post follows my transition to building a data science blog powered by Jupyter and Hexo, the obstacles I came up against, and the solutions I came to employ.
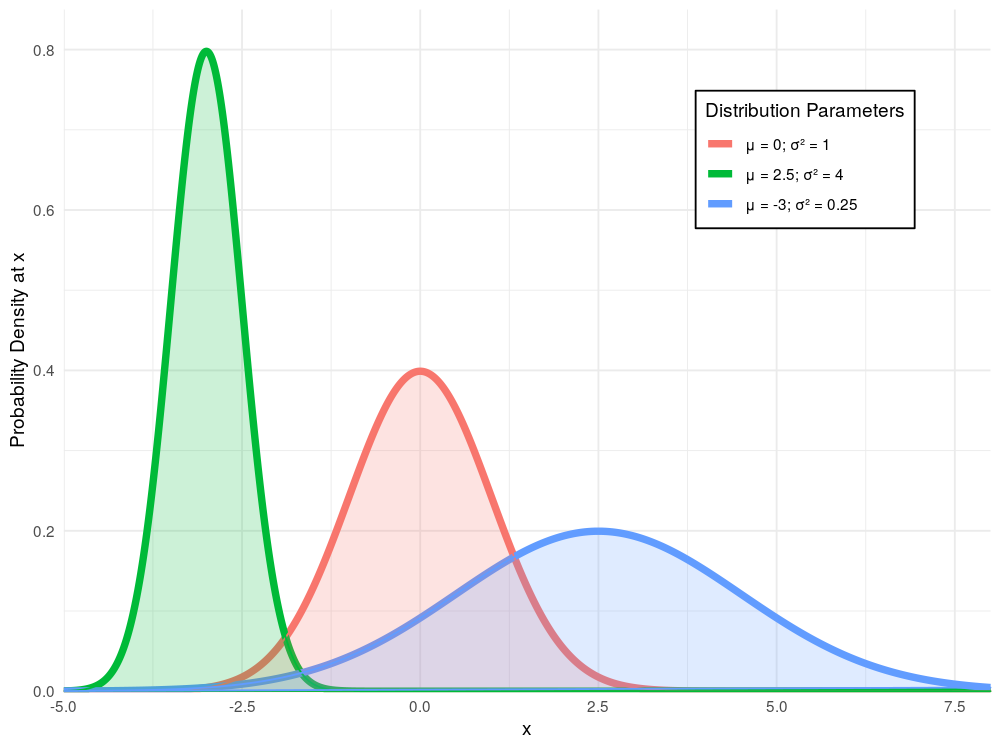
Generating Normal Random Variables - Part 1: Inverse Transform Sampling
The normal distribution is one of the most important developments in the history of statistics. As well as its useful statistical properties, it is so well-loved for its omnipresence in the natural world, appearing in all sorts of contexts from epidemiology to quantum mechanics. This blog post, the first in a series of posts discussing how we can generate random normal variables, explores the theory behind and the implementation of inverse transform sampling.
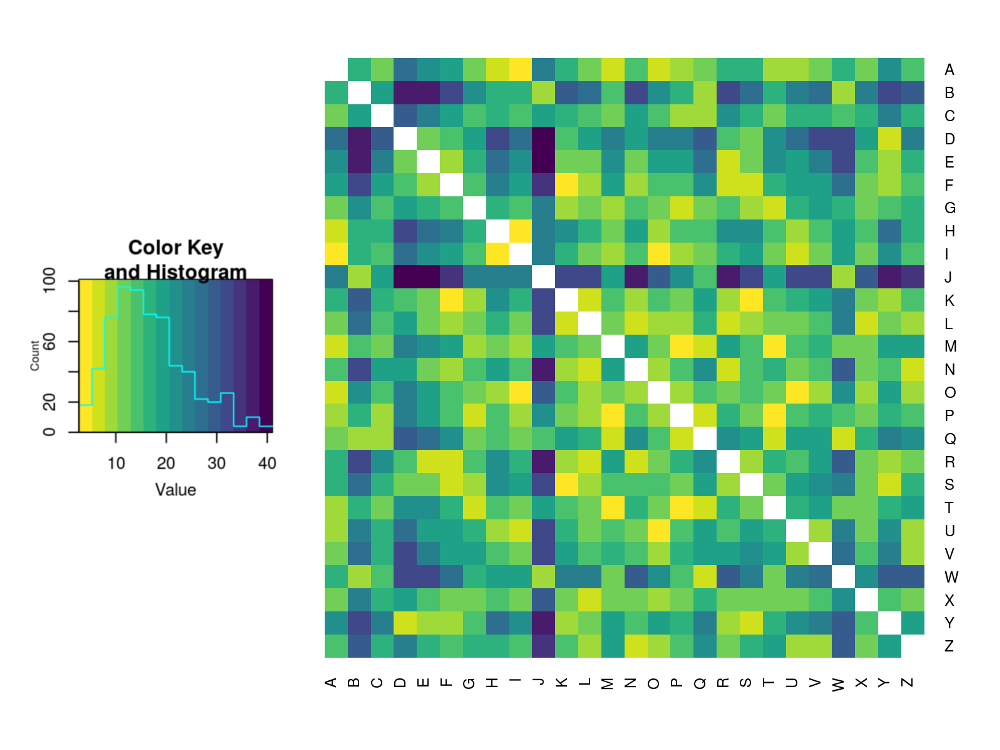
Letter Distributions in the English Language and Their Relations
If you've ever tried to solve a simple cryptography problem, then you may have developed an intuitive sense of where you're most likely to find a letter in a word. For example, 'Q's are rarely at the ends of words whereas 'D's are much more likely to be found there. This post explores this idea and concludes by clustering the letters of the Latin alphabet based on their distributions throughout English words.

Integration Tricks using the Exponential Distribution
Not all integrals are created equally. In this post we look at a particular class of integrals which can be highly troublesome to evaluate. Thankfully, probability theory provides us with a framework that allows us to avoid the standard method of evaluation and by doing so makes our working far less error-prone.
Recent

