

Terminal Velocity in a Vacuum
It is commonly claimed that an object dropped in a vacuum will continue to accelerate indefinitely, reaching arbitrarily high speeds. In fact, even in a vacuum, a falling object has a maximum speed it can reach. In essence, this is the terminal velocity in a vacuum.

Principal Component Regression as Pseudo-Loadings
Principal component regression is a powerful technique from high-dimensional statistics. In this post I offer an alternative interpretation of the procedure as a way of generating PCA loadings for new covariates.

Reflecting on the Reflection Principle
From finance to route planning, the reflection principle is an incredibly versatile technique, capable of transforming seemingly fiendish problems into elegant systems. In this post, I walk through three example applications of the principle.

AI is Not as Smart as You May Think (but That's No Reason Not to Be Worried)
The world of AI is full of hype, making it hard to distinguish real threats from fiction. This post is one of a pair and discusses the current challenges and limitations that AI systems face, particularly with regards the large obstacles that must be overcome before any existential threat from AI could manifest itself. The other details the current use of AI in military applications and the risks that this introduces. In all, these posts aim to present you will an accurate view of the current state of AI and direct focus towards the threats from AI that require the most attention going forwards.

Is it Time to Ditch the MNIST Dataset?
The MNIST dataset is the bread and butter of deep learning. Featuring 70,000 handwritten, numerical digits partitioned into a training and testing set, the dataset is the go to candidate for a large proportion of introductory tutorials, benchmarking tests, and data science showcases. This post questions the suitablility of this dataset for such uses, attributing this shortcoming to the excessive simplicity of the challenge it presents when tackled with modern machine learning tools. Additionally, we look at alternatives to the dataset that demonstrate a more appropriate challenge without fundamentally changing the learning problem.
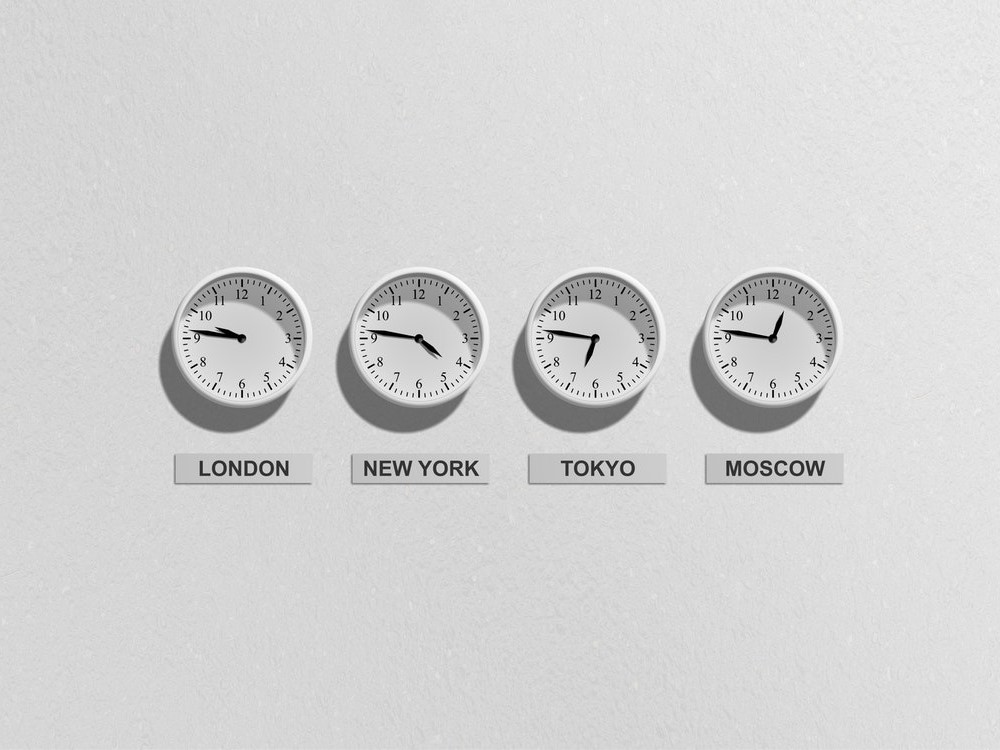
An Analysis of Strange Timezones
Timezones are strange things. Be it Chatham Island's 45-minute offset or West Bank's ethnically divided use of daylight saving, it almost seems like the timezones of the world were chosen to baffle. In this post we ask which capital city has a timezone that differs the most from what would be expected given its longtitude. Any guesses?

#AdventGate—The shocking secret Big Advent doesn't want you to know
Don't waste your tin foil wrapping up your turkey when fashioning it into a hat is far more in need this Christmas. In this post I will reveal how advent calendar makers the world over, have been lying to you about. So launch your VPN and delete your cookies, we're about to take down Big Advent.

Pymetrics Reenvisioned: Using statistics to balance risk and reward when faced with uncertainty
Reinforcement learning is a current hot topic in the world of data science. In this post, we look at how concepts from this area, in particular effective policies for the multi-armed bandit problem, can be applied to a job application assessment ran by pymetrics.

Upon Reflection: dunnhumby
In the first installment of this new blog post series, I will be discussing my summer internship working at the global customer data science firm, dunnhumby. In doing so, I will discuss the elements that tasks up my work, the challenges I faced in completing them, and the lessons I learnt in the process.
Paradoxical Tournaments
Deciding the winner of a round-robin tournament is no simple task. The most naïve approach can easily be faltered by the existence of $k$-paradoxical tournaments. But what are these tournaments and what do we know about them? There is surprisingly little discussion on the topic and so, in this post, I plan to collate various pieces of knowledge on the subject into one succinct guide.
Recent
