

This post is one of a two-part narrative discussing the need to focus on the current, pressing concerns with AI, rather than obsessing with the distracting dangers that lie decades away.
This post will discuss how AI is perhaps not as intelligent as the mass media or film industry would lead you to believe by focusing on examples of its shortcomings and limitations. The other half of this pair is written by Orlanda Gill—a National Security Studies master’s student, at King’s College London—in which she discusses the inherent risks that stem from the current implementation of sub-par AI systems in military applications.
Introduction
Partly due to the influence of many recent AI-centred films gaining mainstream popularity, the technological zeitgeist of this last decade has slowly morphed to become generally fearful and expectant of a looming AI apocalypse. Movies such as Ex Machina and Blade Runner 2049, or the hit television series Black Mirror’s Metalhead all depict a world in which the every-growing power of AI systems has led to an existential threat to humanity at large. Tracing back even further, we can see more examples of this train of thought; The Terminator, 2001: A Space Odyssey, and I, Robot all warn of the same dark fate.
This depressing forecast has greatly penetrated the public consciousness: A 2018 survey conducted by the Center for the Governance of AI of 2,000 US adults found that the average respondent ranked AI concerns of the future such as critical AI safety failures and near-extinction events as nearly as important as present day concerns with AI. A similar survey conducted by the Royal Society, likewise showed that the general public is far more concerned by the notion that a robot—deriving its decisions from misaligned AI—may one day cause them physical harm than the often subtle ways that AI systems can currently cause damage.
That is not to say that we shouldn’t worry at all about the long-term risks of AI. They certainly do exist and are worthy of attention, just not at the detriment of focusing on more pressing issues that we will definitely be faced with over the coming decade. I think that Andrew Ng, infamous AI and machine learning researcher, summarises this view best.
Worrying about AI evil superintelligence today is like worrying about overpopulation on the planet Mars. We haven’t even landed on the planet yet!
The key message is that although AI has a large potential for existential threat, we are still a long, long way from such a world. The rate of development of AI is often exaggerated by a headline-hungry news media. In reality, despite the occasional small breakthrough, the current progress of AI is built far more on small steps than large leaps. On top of this, modern AI approaches (especially those taking advantage of neural networks) have severe limitations that researchers are struggling to overcome. In fact, many of the “cutting-edge” AI algorithms used by leading tech firms this decade were popular statistical literature of the 1980s but now with more data and faster processors thrown at them.
This is the point that I want to demonstrate with this post. Modern AI systems are still lacking maturity and there are serious obstacles that we must overcome before any threat from AI could possibly present itself. Despite these limitations, however, military implementations of AI systems are starting to become mainstream. This is a real threat of AI: biased, unreliable, and opaque algorithms being used to determine who lives and who dies. This is not the imaginings of a sci-fi film writer’s creative mind but a real threat that the world is facing right now. The current state of the military’s relationship with AI is discussed in-depth in this post’s counterpart.
I would highly recommend giving this sister-piece a read to gain a rounded picture of the current state of the threats from AI, both from a technological (me) and humanitarian (Orlanda) perspective. For now, let’s begin our exploration of the shortcomings of modern AI systems. What challenges do they face and how does this limit their utility?
Part I: Generalisation
The first of two key challenges we will look at is that of generalisation. That is, how do modern AI systems react to new, unseen scenarios. We will focus on a particular subset of AI, known as neural networks, which are commonly used in computer vision and strategic decision-making. These attempt to mimic the structure of the human brain, in order to capture complexity in the data they are trained with, that conventional methods would struggle to. The flip side of this is that, in trying to explain the intricacies of the data they have seen before, they can become incapable of handling any new inputs that deviate from what they’re used to. Aside from training these models on literally every possible scenario that could arise, it becomes extremely difficult to manage this uncertainty or even to predict when things might go wrong.
The (Not So) Beautiful Game
Luckily for us, when things do go wrong, they can be rather amusing.
Out of all of the examples of AI systems failing I have come across (and boy, are there a lot), the following is easily my favourite. It is taken from this 2019 paper and concerns the use of neural networks to teach two AI agents how to take part in a penalty shootout. The red agent plays the goalkeeper whilst the blue agent plays the shooter. The two agents were trained by using a technique known as Generative Adversial Networks, in which the computer ‘plays itself’ a vast number of times, improving the skill levels of both agents in the process. After a billion or so ‘practice sessions’ the agents look like this:
They may not be ready for the Premier League just yet (or perhaps even the school playground) but at least we can recognise their behaviour as playing a game of penalty shootout. The shooter knows where to aim and can kick the ball with reasonable accuracy, and the goalkeeper makes valiant attempts at diving for the ball.
The final scoreboard (7-11) would suggest that the shooter is doing a slightly better job than the goalkeeper. The aim of the research team behind the paper was to turn this around. They attempted to adjust the goalkeeper’s defence strategy so that the shooter would find it more difficult to score. What makes this process interesting though, is that they didn’t attempt to do it by making the goalkeeper dive better, move faster, or more accurately prediction the ball’s path. Instead, they just told it to lie down:
You would think that this strategy would be a recipe for defeat and yet it completely stumps the shooter AI, leaving the keeper to finish with a comfortable 7-point lead. Forget scoring a goal, the shooter can barely even walk anymore! It is worth emphasing that the shooter agent in this example is the exact same as in the previous one; it is only the changing behaviour of the keeper that causes the shooter to struggle in response. This is because the input the shooter is now recieving is a long way from what it is used to seeing. The complexity of the network behind its motion has been trained to respond to the fine details of the ball’s position and goalkeeper’s stance and in doing so has made it incapable of handling any input that deviates significantly from this norm.
The need to have generalisable models is extremely important. Take self-driving cars for example. If a human were to drive down a residential street and hear an ice-cream van’s melody echo around the houses, they would likely be extra cautious as a child could run out at any moment desperate to grab a snack before the van gets away. Most humans have never been exposed to a scenario in which they needed to urgently brake to avoid a ice-cream-obsessed child, and yet we know that it is a possibility anyway. Would an AI system necessarily understand how to respond to this or the thousands of other similar edge-cases without first being exposed to it and risking finding out the hard way?
Linking in with Orlanda’s post about the use of this type of AI in military applications, should we really be using systems that can be tricked so easily into performly completely erratically when the consequences are so significant?
Cheaters Never Prosper
Whereas the example above failed to generalise to significantly different input data, it is not hard to come across examples in which only seemingly small changes to the input can lead to wildly different behaviour by an AI. This is commonly caused by overfitting, in which a neural network gives too much weight to certain inputs and so becomes highly susceptible to changes in their values. This is most severe when the input data contains a feature that is not present in typical real-world testing data. In this case, the neural network can have an easy time training, outputting high confidence in its own abilities, even though its predictions are largely based on features of the training data that do not generalise. Then when it comes time to test the model on unseen data, catastrophe can be unleashed.
This can almost be thought of as the neural network ‘cheating’. Like a school-child using notes written up their sleeves to ace a test, training a model on unrepresentative data can lead to it performing better than it naturally should. Then, when exposed to real world data, the true errors of the model can become evident, just as the school-child might discover when they are forced to resit the test under the watchful eye of an invigilator. Furthermore, the school-child may now do worse since their confidence in their ability to always be able to cheat led them to never bothering to revise. Likewise, a model that was trained on biased data may perform worse on new data than otherwise would be the case.
A classic example of this is the story of the self-driving car, ALVINN. Perhaps not as slick-looking as a Tesla, but considering it was first let loose on UK roads in 1989, arguably more adventurous.

ALVINN was powered by the same neural network machinary used in almost all modern self-driving systems. Admittedly, the networks were of a much smaller scale to match the limited computational power of the era but the idea was there. Despite its primitivity, ALVINN was surprisingly successful; capable of independently navigating a simple road with ease.
Things took a turn for the worst, however, when ALVINN found itself approaching a bridge. It’s previously calm and controlled driving gave way to erratic swerving, dangerously twisting out of control until the human monitoring the vehicle was forced to take hold of the wheel to avoid a crash. What went wrong?
After some time digging through the data, the researchers behind the experiment found that ALVINN had (in a sense) been cheating. ALVINN’s training had mainly consisted of driving down roads with a grass verge along the side. It had therefore learned that if it could just keep this green strip on its left parallel to where it was heading, everything would be alright. That is, alright until that grassy guideline gives way to the stone walls of a bridge. Since ALVINN had weighted the position of this green patch so highly in its decision making, it struggled to know what to do without it, resorting to flailing around wildly, hoping to come across it again and restore order.
Another story from AI folklore tells of a US Army research venture in which a team of AI experts attempted to build a neural network that could detect camouflaged tanks given a candidate image. After working through the standard machine learning techniques of the era, the researchers ended up with a model that was remarkably accurate. The team then allegedly handed their final product into the Pentagon for review, which promptly handed it back, complaining that their own tests found the neural network to perform no better than a coin-toss. The story goes that the researcher’s dataset had an inherent bias—the photos of camouflaged tanks had been taken on cloudy days, whilst the photos of tank-less forests had been taken on sunny days. Since the overall colour-temperature of the image correlated so well with the presence of a tank, the model never bothered to actually learn how to detect a tank but rather how to read the weather!
Although this exact tale may well be apocryphal, there are many well-documented cases in which similar (though often more subtle) scenarios have arose. A common example of this is a neural network developed by Google for labeling images. One challenge it had to tackle was differentiating between images of Huskies and Wolves. It turns out the network’s decision was based heavily on the presence of grass or snow. This assumption wasn’t awful in most cases and resulted in high internal prediction accuracy, but present the model with a picture of a wolf on grass and it may be a little too confident in telling you to go and give it a pet.
These examples are obviously extremes in which it is clear how the neural network overfitted to the input data (or at least in hindsight it is - it took the original researchers some time to piece together what was going wrong with both examples). In most cases though, the differences between the training and testing data may be subtle and remain unknown until too late.
Part II: Robustness
The second (and final) challenge we will discuss regards that lack of robustness that modern AI systems can be subject too. Although robustness has a rigourous statistical definition, in this post I want to talk about it in a more general sense, relating to how difficult it is to break a model and how easily unwanted predictive factors can ‘leak’ into our predictions. We will again mainly focus on the use of neural networks for computer vision as this is such a critical area of modern AI research, though we will also take a detour to discuss the use of AI for predictive crime models and the difficult ethical discussions this can lead to.
Invisible Attacks
As is the way of the technological world, as soon as someone develops a new algorithm or tool, another will crack open their PC to start breaking it. We will start by looking at a technique known as one pixel attacks (or its slightly sexier name, pixel-hacking). This is a method used to trick neural networks designed to label images by making minimal changes to the input data. In particular, we take an image that such a neural network can confidently label and, by changing just one lone pixel, completely alter the network’s prediction. A selection of such attacks is shown below, the blue label giving the networks prediction after pixel-hacking has occured alongside its confidence in the choice.![]()
For such low resolution images, the editing of one pixel is certainly noticable. For a high resolution image, however, only the most eager-eyed people might be able to notice anything wrong, and even then they may need to be prompted to bother looking for inconsistencies in the first place.
These attacks work by exploiting the underlying structure of the neural network. In trying to capture all the detail of the training data the model is presented with, it may unknowingly assign an inappropriately heavy weighting to particular pixels in determining the overall label of the image. By tweaking the value of such a pixel, the output of the model can be altered significantly.
With enough attention though, it is likely that these attacks could be foiled by even a non-technologist. We’re not done yet though. If changing one pixel can affect a model’s predictions so significantly, what can be done by controlling all of them?
This leads us into the discussion of random-noise attacks. In this, an image is combined with carefully choosen random noise in such a way that the resulting image is virtually indistinguishable from the original yet the neural network being attacked drastically changes its prediction. One example of such an attack is below.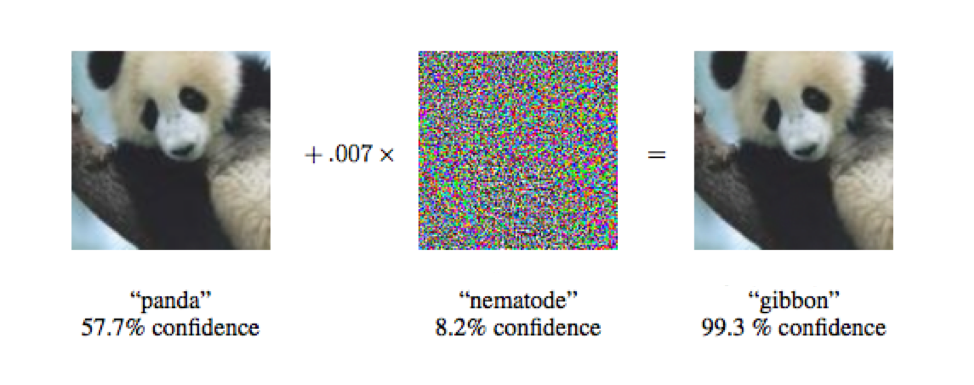
Apart from the image on the right being slightly more noisy than that on the left, there is really nothing to distinguish the two by eye. Given only the second image, it is likely that even with the aid of computation, you wouldn’t be able to check whether it was a carefully crafted adversial example without first letting the neural network loose on the image.
At least with the generalisation issue above, there was a clear reason as to why predictions were going awry under new inputs. With this example however, that is not the case—a far more worrying outcome.
Pedal to the Metal
The above attacks worked by altering the image in its digital form. Adversarial attacks against neural networks are not limited to this approach, however. This is demonstrated in the following paper in which a research team attempt to fool a self-driving car’s street sign detection model by applying small black and white pieces of tape to a physical stop sign. The team aimed to mimic the look of graffiti naturally found on stop signs to make the perturbations less suspicious to a human driver. The chosen tape layout is shown on the right-hand side of the image below.

With the addition of only four small pieces of monochrome tape, the car’s interpretation of the sign went straight from ‘stop’ to a confident prediction that this was a 45 km/h speed limit sign. For obvious reasons, this system was never tested outside of the lab, but who is to know how a self-driving car would react if it came across such an altered sign in the real world. Worse still, if a stop sign can be made to read as a 45 km/h speed limit sign, who’s to say that the same isn’t possible for higher speed limits.
With Great Power Comes Great Fragility
The final example I wish to discuss differs from the previous two but still relates to the issue of robustness discussed above (or at least the loose, non-statistical definition). This involves the use of neural networks for predicting crime. Although not quite on the Minority Report level of predicting the exact location, offender, and circumstance of a crime, these algorithms are designed to indicate which areas might be a hotspot for crime over the next few hours/days/weeks so that more police officers can be allocated to patrol there. For example, it is known that burglars are likely to visit the same house—or at least the same neighbourhood—in the weeks following an initial break-in. Some research even suggests that the repeat burglary rate within six months of the first incident could be as high as 51%. Taking into account information such as this and many other predictors such as weather and time of year, it is possible to build a model that can reasonably predict where crime is more likely to take place.
In a particular example of such an algorithm discussed in Cathy O’Neil’s Weapons of Math Destruction, the team behind the model made it clear that they did not include any demographic predictors of each area’s race in an attempt to remove any racial bias that their model could develop. Despite this, a later analysis of the model’s behaviour found that it did have racial biases. Where did these come from? The answer comes in the form of ZIP codes. Although the race wasn’t included directly in the input data, the model had managed to pick up patterns from the available predictors that allowed it to somewhat piece together the racial demographic of each area, influencing its predictions in the process.
There are many examples in data science in which a variable—deliberately left out of the training data—did in fact influence the model’s predictions through another correlated proxy variable that was included. Avoiding this can often be difficult and involves strict ethical vigilance.
Conclusion
The future has a lot in store for the field of AI. There is no doubt that over the coming decades there will be great innovations, important discoveries, and—as a consequence—serious dilemmas to discuss. We will be faced with great challenges and will have to work hard to overcome them. It is important, however, that we do not let a fear of the future prevent us from seeing the real risks that exist today.
I hope that this post has convinced you that the current state of AI is perhaps not as powerful as a bystander would be led to believe. Yes, great work with great outcomes is being undertaken, but often when you pull back the curtain, you can find AI systems that are still immature and struggle to adapt. The challenges discussed in this post are only the tip of the iceberg for what AI must overcome in the following decades before near human-level intelligence could be reached and any threat could begin to manifest itself.
However, this long road to success has proved not to be an obstacle for certain parties interested in AI applications. Robot Wars Judge and Professor of AI and Robotics Noel Sharkley has been talking since the mid-noughties about the steady adoption of AI system in military contexts. Systems similar to those mentioned above that are so easily fooled or can behave so erratically are being implemented right now and yet relatively little uproar is being made in response.
The first step in making a difference is learning the lay of the land. To do this, I would recommend reading the other post in this series in which my colleague Orlanda explores the current use of AI in military settings and the risks this presents. I hope that these two posts combined will aid your considerations regarding the importance of both current and future risks of AI.



